Type "how do i" into a search bar and watch it finish your thought before you do. Ask your phone to "remind me to call mom tomorrow" and watch it actually understand what you mean. Send an email in Hindi and have it land, fluently, in someone's English inbox. None of this works without one specific branch of artificial intelligence quietly doing the heavy lifting underneath.
So, what is natural language processing (NLP), exactly? In plain terms, NLP is the field of AI focused on teaching computers to read, understand, and generate human language, the messy, ambiguous, full-of-slang language we actually speak and write, not the tidy rows of numbers computers normally prefer. It's the bridge between "how humans talk" and "what a machine can compute."
NLP isn't a single tool, it's an entire toolbox, and like most modern AI, it sits inside the broader discipline of machine learning. If the difference between AI that's truly "learned" something and AI that's just following fixed rules feels blurry, our guide on what is the difference between AI and automation is a good place to start before diving into NLP specifically.
- Language as numbers: NLP converts words and sentences into numerical "embeddings" a computer can mathematically compare.
- A multi-step pipeline: text is tokenized, normalized, tagged, and modeled before any output is produced.
- Two directions: NLP covers both understanding language (NLU) and generating it (NLG), like a chatbot's reply.
- Transformers changed everything: modern NLP relies heavily on the same attention-based architecture behind chatbots and translators.
- It's everywhere already: search, spam filters, autocomplete, voice assistants, and translation all run on NLP daily.
01The Simple Answer: Teaching Computers to Understand Language
Computers are naturally good at numbers and naturally terrible at language. They don't know that "bank" means something different in "river bank" versus "savings bank," and they have no built-in sense of grammar, tone, or sarcasm. NLP exists to close that gap, by converting unstructured text into structured data a model can actually work with.
This is the same basic trick used across most modern AI systems. If you've read our explainer on how does AI recognize faces in photos, you've already seen the pattern: a system takes something messy and human, in that case a face, and turns it into a clean set of numbers it can measure and compare. NLP does the exact same thing with words. Every word, sentence, or document gets converted into an "embedding," a long list of numbers that captures its meaning, so that words used in similar ways end up sitting close together in that mathematical space.
Once language has been turned into numbers, a trained model can do almost anything with it: classify it, translate it, summarize it, or generate a brand-new sentence in reply. If the idea of "training" a model on data is new to you, our guide on what is machine learning and how is it trained covers the fundamentals in plain language before we go further.
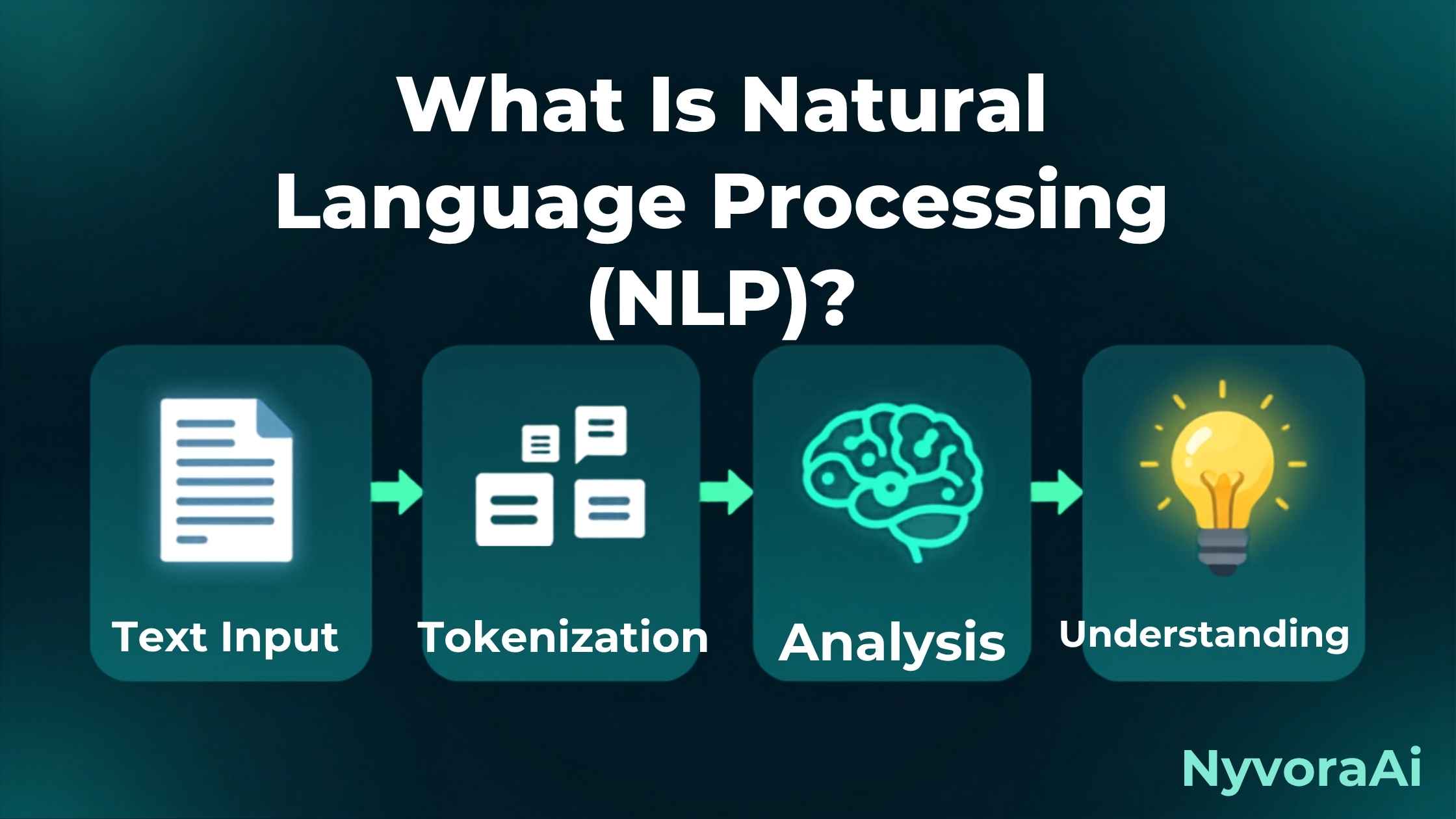
02Step-by-Step: How NLP Turns Text Into Meaning
Here's the journey a sentence takes from raw text to a usable result:
Tokenization: Breaking Text Into Pieces
The first step splits a sentence into smaller units called tokens, usually words or pieces of words. "I'm loving this" might become ["I", "'m", "loving", "this"]. This gives the model bite-sized chunks to work with instead of one solid block of text.
Text Normalization: Cleaning Things Up
Tokens get standardized: lowercasing, removing stray punctuation, correcting common typos, and sometimes reducing words to their root form, so "running," "ran," and "runs" can all be recognized as related to "run."
Vectorization: Turning Words Into Numbers
Each cleaned token is converted into a numerical embedding. Modern systems learn these embeddings from enormous text corpora, since meaning only becomes statistically reliable after a model has seen a word used correctly millions of times. That's part of why our piece on why does AI need so much data to train is so relevant here.
Parsing & Tagging: Adding Grammar and Structure
The system tags each token's part of speech (noun, verb, adjective) and identifies named entities like people, places, brands, or dates, building a structural map of the sentence on top of the raw numbers.
Model Processing: Understanding Context
The tagged, vectorized sentence is run through a trained model, in most modern systems a transformer, which weighs how every word relates to every other word in context before deciding what the sentence actually means. Our guide on what is a transformer model in AI breaks this exact mechanism down in detail.
Output: Producing a Result
Finally, the model produces something useful: a translated sentence, a spam/not-spam label, a sentiment score, a search ranking, or, in the case of a chatbot, an entirely new generated reply.
03Interactive Demo: See NLP Tag a Real Sentence
Here's a sample product review. Click the buttons below to see how different NLP tasks "read" the exact same sentence in different ways.
Watch how tokenization, grammar tagging, entity recognition, and sentiment analysis each interpret this sentence
04From Rule-Based Systems to Transformers
NLP didn't start with deep learning. Early systems in the 1960s through 1990s relied on hand-written grammar rules and dictionaries, painstakingly coded by linguists for every exception language could throw at them. They were brittle: a sentence structured slightly differently than expected would simply break the system.
Statistical NLP, which dominated from the late 1990s through the 2010s, replaced hard-coded rules with probabilities learned from real text, a major improvement, but these models still treated context in a fairly narrow window, usually just a handful of nearby words. The real shift came with deep learning, and specifically with transformer architectures, which can weigh relationships between every word in a sentence (or even an entire document) simultaneously, rather than one neighbor at a time.
This is also where NLP splits into two related but distinct directions: natural language understanding (NLU), which is about interpreting what a sentence means, and natural language generation (NLG), which is about producing new, coherent text. A chatbot needs both. Our explainer on how does AI decide what to say next focuses specifically on the generation side, predicting the next word in a sequence, which is exactly how modern chatbots write their replies.
It's also worth knowing that the heavy lifting of "learning language" happens long before you ever type a message. Training a large NLP model on a huge text corpus takes enormous computing time, but using that finished model to read your sentence happens almost instantly. Our piece on AI inference vs training walks through that distinction in detail.
| Era | Approach | Real-World Analogy |
|---|---|---|
| Rule-Based (1960s–1990s) | Hand-coded grammar rules and dictionaries | Like a strict grammar teacher who can't handle slang |
| Statistical NLP (1990s–2010s) | Probabilities learned from text frequency | Like guessing the next word from habit, not understanding |
| Deep Learning / Embeddings (2013+) | Words represented as vectors in meaning-space | Like placing every word on a map by what it's close to |
| Transformers (2017+) | Attention across the whole sentence or document at once | Like reading an entire paragraph before forming an opinion |
05Where You Already Use NLP Every Day
NLP isn't a futuristic concept, it's already running quietly in tools you probably used this morning:
Search Engines
Search understands the intent behind your query, not just the exact keywords you typed, matching meaning rather than literal text.
Chatbots & Virtual Assistants
From customer support bots to Siri and Alexa, NLP parses what you said and generates a coherent, relevant reply.
Machine Translation
Tools like Google Translate use NLP to convert meaning, not just words, between languages with very different grammar.
Spam & Content Moderation
Email filters and social platforms use NLP to flag spam, scams, and harmful content based on language patterns, not just keywords.
Sentiment Analysis
Brands track product reviews and social mentions automatically, measuring whether the language used is positive, negative, or neutral.
Autocomplete & Spell Check
Predictive text and grammar correction tools use the same underlying language modeling that powers far larger NLP systems.
Worth noting: not every personalization system online runs on language at all. YouTube's feed, for example, leans far more heavily on behavioral signals like watch time than on anything you've typed or said, see our breakdown of how do AI recommendations work on YouTube for a useful contrast between language-based AI and behavior-based AI.
06How Accurate Is It? (And Where Does It Still Struggle?)
Modern NLP, especially transformer-based systems, has gotten remarkably good at understanding context, tone, and even implied meaning. But language is genuinely one of the hardest things to model, because so much of it depends on shared culture, situation, and unspoken assumptions.
Context Is Everything
The same sentence can mean completely different things depending on who's speaking, the platform it's posted on, and what came immediately before it. NLP models do their best to use surrounding context, but they don't have a lived human life to draw on.
Where NLP Still Falls Short:
Sarcasm and Dry Humor
"Oh great, another Monday" reads as positive on the surface but negative in tone, a gap that still trips up even strong models without extra context cues.
Low-Resource Languages
NLP performs best on languages with massive amounts of available text, like English. Languages with smaller digital footprints often get noticeably weaker support.
Ambiguous Phrasing
"I saw her duck" could mean an animal or an action. Models lean on context to resolve this, but genuinely ambiguous sentences can still confuse them.
Bias Inherited From Training Data
Since models learn from real-world text, they can absorb and repeat the same stereotypes, slang biases, or skewed associations present in that data.
Limited Context Windows
Even powerful models can only "see" a certain amount of surrounding text at once, so very long documents or conversations can lose earlier context.
07The Privacy and Ethics Debate
A technology that can read and interpret human language at scale naturally raises bigger questions than just accuracy:
- Training data sourcing: large NLP models are trained on enormous amounts of text scraped from the public internet, raising questions about consent and copyright.
- Surveillance potential: the same sentiment and entity-extraction techniques used for customer reviews can also be applied to monitor private messages or employee communications.
- Misinformation at scale: language generation makes it cheap to produce large volumes of convincing but false or misleading text.
- Bias and fairness: language models can reinforce stereotypes present in their training data if left unchecked.
- Regulation: frameworks like the EU AI Act now place specific transparency requirements on systems that generate or analyze human language at scale.
As a user, the most practical safeguard is simply being aware that anything you type into a chatbot, review box, or comment section may be processed, analyzed, and in some cases used to improve future models, depending on the platform's specific privacy policy.
08Frequently Asked Questions
What is natural language processing (NLP)?
How does NLP work step by step?
What is the difference between NLP and machine learning?
What are some everyday examples of NLP?
Can NLP understand sarcasm and tone?
Is ChatGPT an example of NLP?
What's the difference between NLP and a transformer model?
Do I need to know coding to understand NLP?
Written by the NyvoraAI Team
We're passionate about making complex AI technology accessible to everyone. This guide breaks down natural language processing into digestible concepts. Questions? We're here to help!