If you've ever wondered how a computer can suddenly recognize a cat in a photo, translate a foreign language instantly, or predict what movie you'll want to watch next, the answer is almost always machine learning. But here's the thing: the computer wasn't "programmed" to do these things in the traditional sense. No human wrote a line of code that said, "If you see pointy ears and whiskers, it's a cat."
Instead, the computer was trained. It was shown millions of examples until it figured out the patterns for itself. This shift from explicit programming to pattern-based learning is the single biggest revolution in computing history. But how does it actually work? And what does it mean to "train" a piece of software?
In this guide, we're going to pull back the curtain on the training process. We'll explain what machine learning is, how models learn from data, and why this technology is reshaping everything from healthcare to your daily social media feed.
Machine learning isn't magic; it's advanced statistics and pattern recognition at a massive scale.
- The Goal: To create systems that improve their performance on a task through experience (data) rather than explicit instructions.
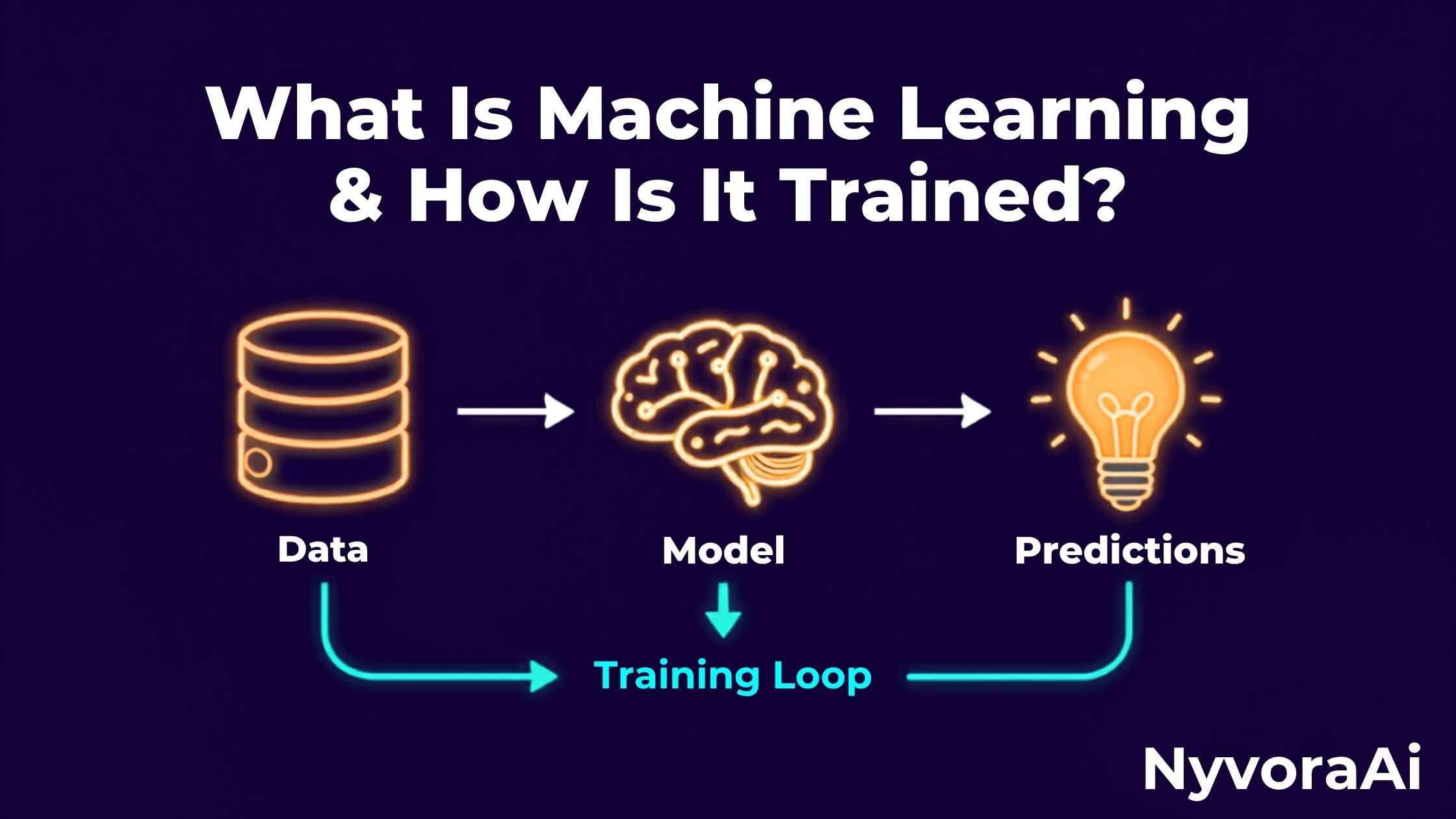
- The Process: Training involves feeding data to a model, having it make predictions, calculating the error, and adjusting its internal parameters to reduce that error.
- The Fuel: Data is the most critical component. The quality and quantity of data directly determine how smart the model becomes.
- The Result: A "trained model" that can generalize its knowledge to handle new, unseen information accurately.
01What Is Machine Learning, Actually?
At its simplest, machine learning (ML) is a subset of artificial intelligence focused on building systems that learn from data. In traditional programming, a human provides the rules and the data, and the computer provides the answers. In machine learning, the human provides the data and the answers, and the computer figures out the rules.
Think of it like teaching a child to identify fruits. You don't give them a dictionary definition of an apple. Instead, you show them ten different apples—some red, some green, some with spots. Eventually, they recognize the general pattern of "apple-ness" and can identify a new apple they've never seen before. That is exactly how machine learning works, just with billions of data points instead of ten.
It's important to distinguish this from simple automation. While automation follows a fixed set of steps, ML is dynamic. It adapts. If you want to understand the boundary between these two concepts, our guide on the difference between AI and automation provides a clear, practical breakdown.
02How Is a Machine Learning Model Trained?
Training a model is a rigorous, iterative process. It’s not as simple as hitting a "learn" button. Here is the step-by-step journey from raw data to a functional AI:
Step 1: Data Preparation and Tokenization
Before any learning happens, the data must be cleaned and formatted. Computers don't understand words or images; they understand numbers. For text, this involves a process called tokenization, where sentences are broken down into smaller chunks (tokens) and converted into numerical vectors. If you're curious about the nitty-gritty of how text becomes math, check out our deep dive on what tokenization is in AI.
Step 2: The Prediction Phase
The model takes a piece of data and makes a prediction based on its current internal settings (called parameters or weights). In the beginning, these settings are random, so the predictions are terrible. It might look at a picture of a dog and guess "toaster."
Step 3: Calculating the Loss
The system compares its prediction to the actual correct answer (the "label"). The difference between the guess and the reality is called the loss or error. The goal of training is to get this loss number as close to zero as possible.
Step 4: Backpropagation and Adjustment
This is the "learning" part. Using a mathematical technique called backpropagation, the model looks at its error and adjusts its billions of internal parameters slightly to make the same mistake less likely next time. It’s a process of constant, microscopic self-correction.
03Why Does ML Need So Much Data?
You often hear that AI needs "big data," but why? The reason is generalization. If you only show a machine learning model pictures of white cats, it will learn that "cat" means "white furry animal." When it sees a black cat, it will fail. By feeding it millions of images of cats in every color, lighting condition, and pose, the model learns the fundamental essence of a cat rather than just memorizing specific examples.
This is why modern Large Language Models (LLMs) are trained on essentially the entire public internet. They need that sheer volume of diverse information to understand nuance, context, and rare scenarios. We explore this necessity in detail in our article on why AI needs so much data to train.
The Scale of Modern Training
State-of-the-art models in 2026 are trained on datasets containing trillions of tokens. To put that in perspective, one trillion tokens is roughly equivalent to 20 million books. The computational power required to process this is immense, often requiring thousands of specialized GPUs running for months.
04The Three Main Types of Machine Learning
Not all learning happens the same way. Depending on the goal, engineers use different training strategies:
- Supervised Learning: The model is given data with correct answers (labels). It's like a student with a textbook and an answer key. This is used for things like spam filtering or image recognition.
- Unsupervised Learning: The model is given data without labels and must find hidden structures or patterns on its own. It's like giving a student a pile of mixed-up puzzle pieces and asking them to sort them by shape or color without seeing the box art.
- Reinforcement Learning: The model learns through trial and error by interacting with an environment. It gets "rewards" for good actions and "penalties" for bad ones. This is how AI learns to play complex video games or control robots.
05Challenges in Training: Bias and Hallucinations
Training isn't perfect. Because models learn from human-generated data, they inevitably pick up human biases. If the historical data used to train a hiring algorithm contains bias against certain demographics, the AI will learn and amplify that bias. This is a major ethical challenge in the field.
Additionally, models can suffer from "overfitting," where they memorize the training data so perfectly that they fail to handle new, slightly different information. They become experts at the past but useless for the future. Ensuring a model is robust and fair requires rigorous testing and "fine-tuning" after the initial training phase.
06The Architecture Behind the Magic: Transformers
Most of the AI you interact with today—from translation apps to chatbots—is built on a specific architecture called the Transformer. Introduced in 2017, Transformers allow models to pay attention to different parts of a sentence simultaneously, understanding context much better than previous methods. If you want to understand the engine powering the modern AI boom, our guide on what a Transformer model is breaks it down simply.
This architecture has also revolutionized fields like language translation. Instead of translating word-for-word, modern ML models understand the sentiment and structure of the entire sentence, leading to incredibly natural-sounding results. You can read more about this evolution in our piece on how AI translation works.
07Frequently Asked Questions
What is machine learning in simple terms?
How is a machine learning model trained?
Why does machine learning need so much data?
What is the difference between AI and machine learning?
Can machine learning models make mistakes?
Written by the NyvoraAI Team
We demystify the complex world of AI for everyone. This guide was reviewed for technical accuracy in June 2026. Have a question about how AI learns? Reach out to us—we love talking tech!