There's a moment in 2021 that most people interested in AI probably missed at the time. A group of Stanford researchers published a paper introducing the term "foundation model" and arguing that AI had crossed a fundamental threshold. Not because one model had gotten smarter than another, but because the basic approach to building AI had changed in a way that would ripple through every application, industry, and use case for years to come. That paper's argument turned out to be right, and understanding it helps make sense of why AI suddenly got so useful so fast.
Before I explain foundation models specifically, I want to address something I notice in a lot of AI explainers. They tend to describe these concepts as if everyone reading already has a technical background. Most people don't, and they shouldn't need one to understand why foundation models matter. So this is the version I'd give to a curious, intelligent person who just hasn't been inside an AI research lab.
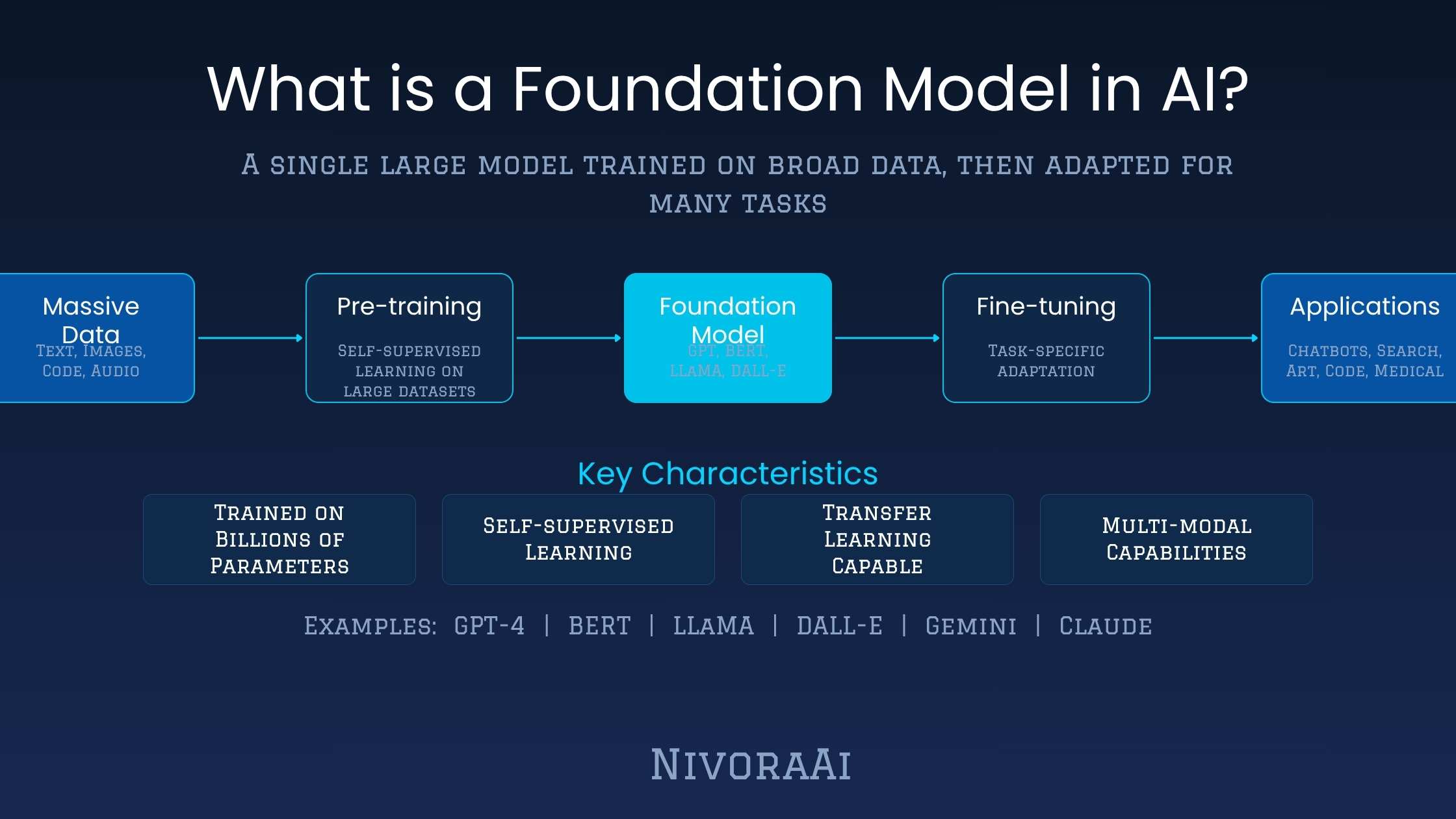
- The core idea: A foundation model is a large AI model trained on a huge amount of broad data, designed not for one task but to be adapted for many different tasks afterward.
- Where the name comes from: Stanford researchers coined it in 2021. The "foundation" metaphor comes from the idea that these models form the base layer on which many specific AI applications are built.
- Famous examples: GPT-4, Claude, Llama, Gemini, DALL-E, Stable Diffusion, and Whisper are all foundation models.
- What makes them different: Earlier AI was narrow — trained for one task. Foundation models are general — trained broadly, then adapted. That single shift made AI dramatically more useful and more accessible.
- The relationship to LLMs: Large language models are a type of foundation model focused specifically on text. Not all foundation models are LLMs — image and audio models are foundation models too.
01 What AI Looked Like Before Foundation Models
To appreciate why foundation models matter, it helps to know what came before them. For most of AI's history — even its recent, more impressive history — models were built to do one thing. You wanted to classify whether an email was spam? You trained a model on spam vs non-spam emails. You wanted to translate French to English? You trained a model specifically on French-English text pairs. You wanted to detect cats in photos? You trained a model on images of cats and non-cats.
This approach worked, but it had a brutal limitation: every new task required a new model. Each one needed its own dataset, its own training process, its own evaluation, and its own maintenance as the world changed. A company building AI products had to repeat this entire cycle for every problem they wanted to solve. That made AI expensive, slow to deploy, and accessible mainly to large organisations with the data and engineering resources to do it right.
There were also deeper problems with narrow AI. These models were brittle — they performed well inside the distribution of their training data and fell apart outside it. A spam classifier trained on 2019 emails would start failing badly by 2022 as the language of spam changed. A medical diagnosis model trained on data from one hospital would perform poorly at another hospital with different patient demographics or imaging equipment. Every model was essentially a fragile, specialised tool that needed constant tending.
Researchers started noticing that models trained on enough general data at enough scale seemed to develop broad capabilities spontaneously — capabilities that weren't explicitly trained for. A model trained to predict the next word in text turned out to be good at translation, summarization, answering questions, and writing code, even though it wasn't trained on any of those tasks specifically. This "emergence" of capabilities from scale is central to understanding what foundation models are.
02 What Changed — The Foundation Model Idea
The foundation model concept flips the traditional AI development approach on its head. Instead of starting from a narrow task and building a specialised model for it, you start by training a massive, general model on an enormous and diverse range of data. This model — the foundation — learns broad patterns about language, or images, or audio that aren't specific to any single downstream task.
Once that foundation exists, you can adapt it to specific tasks through a process called fine-tuning — essentially giving the model a much smaller, focused training run to sharpen it for a particular use case. The foundation model brings general intelligence. Fine-tuning adds specific expertise. This is why a single Llama model can be fine-tuned into a medical assistant, a coding tool, a customer support bot, or a legal document analyser — because the general capabilities are already there in the base model, and fine-tuning just directs them.
The economics of this shift are as important as the technical change. Training a frontier foundation model costs hundreds of millions of dollars and months of time. But once trained, thousands of companies can adapt it for their specific needs through relatively cheap fine-tuning or prompt engineering. The upfront cost is enormous but shared, and the incremental cost of each new application is tiny compared to building from scratch every time. That's a fundamentally different economics from pre-foundation-model AI.
03 The Key Properties of a Foundation Model
04 Real Foundation Models You've Probably Already Used
Foundation models aren't an abstract concept — every popular AI tool you've interacted with in the last few years is almost certainly built on one. Here's a look at some of the most widely used ones.
If you want to understand how the open-weight foundation models in that list compare to closed ones in terms of day-to-day capability and cost, our comparison of GPT vs Claude differences is a useful next read. And if you're wondering which foundation model makes the most practical sense to start using, our guide to which LLM is best for beginners in 2026 makes those trade-offs clear.
05 How Foundation Models Actually Get Built
The process has a few distinct phases that are worth understanding, because they explain a lot about how these models behave — and why they sometimes fail in predictable ways.
06 Why Foundation Models Matter to People Who Aren't AI Researchers
All of the above is interesting history and theory. But why does it matter to someone who isn't building AI systems or studying machine learning? I'd argue it matters because foundation models directly shape what you can now do with AI as an individual or an organisation, and understanding the underlying concept helps you make better decisions about which tools to use and how to use them.
The most practical implication is that you're no longer interacting with a narrow AI. When you ask ChatGPT to help with a spreadsheet formula, then ask it to write a poem, then ask it to explain quantum physics, you're not switching between three different systems trained on three different things. You're using one model that learned broadly enough to handle all of that. That's only possible because of the foundation model paradigm.
The second implication is about access. Because foundation models exist and many of them are openly released, the cost of building capable AI products has dropped enormously. A small team in 2026 can build on top of Llama or Mistral and deploy a genuinely capable AI product without the budget that used to be required. This has democratised who gets to build with AI in a way that wouldn't be possible if everyone had to train from scratch. Our analysis of why LLMs are getting cheaper in 2026 explains how the open foundation model ecosystem has driven that cost reduction across the board.
The third implication is about privacy and control. Once you understand that a foundation model's weights are a file that can be downloaded, the possibility of running it locally becomes real. You're not necessarily dependent on a cloud service to access powerful AI — you can run an open-weight foundation model on your own hardware, on your own terms, with none of your data going anywhere. Our step-by-step guide on how to run an LLM on your own computer shows you exactly how to do this with the most accessible open foundation models available.
A common mistake when people first engage with foundation models is treating them as all-knowing oracles. They're not. They have a knowledge cutoff — events after their training data ends aren't known to them. They can hallucinate, confidently stating things that are wrong. They reflect biases present in their training data. And they have no real understanding of truth versus falsehood — they generate plausible-sounding text, which is usually correct but not always. Knowing this helps you use these tools well rather than over-relying on them.
07 Conclusion — The Bigger Picture
A foundation model is, at its core, a large AI model trained on so much data at such scale that it develops broadly useful capabilities — capabilities general enough to be adapted to hundreds of different specific applications through fine-tuning. The term was coined specifically to capture the idea that these models form the base layer on which much of modern AI gets built.
What makes this concept significant isn't just the technical achievement. It's the shift in what's possible. Before foundation models, every AI application required its own bespoke model, its own dataset, its own training process. After foundation models, the pattern flips: train once broadly, adapt cheaply and repeatedly for specific needs. That shift has made AI dramatically more accessible, dramatically cheaper to build on, and increasingly embedded in tools and products that most people use without necessarily knowing there's a foundation model underneath.
If you've ever used a text autocomplete that feels surprisingly smart, an AI writing assistant, a voice transcription tool, or an image generator, you've used a product built on a foundation model. Understanding what those words mean — and why the concept was a genuine turning point in AI's history — gives you a much clearer picture of what this technology actually is, what its real limits are, and where it's likely to go next. That's useful knowledge whether you're building with AI, making business decisions about it, or just trying to understand the world a little better.
08 Frequently Asked Questions
What is a foundation model in AI?
What is the difference between a foundation model and an LLM?
Why are foundation models important?
What are examples of foundation models?
Can I use a foundation model for free?

Written by Varun Lalwani
Varun covers AI fundamentals, large language models, and the practical side of building with open-source AI. Published July 2026. Questions? Contact the team or learn about our mission. Get new guides via our RSS feed.